山東朱氏藥業集團榮獲菏澤市高新技術企業獎,彰顯醫療器械生產卓越實力

山東朱氏藥業集團憑借其在醫療器械生產領域的創新成果和突出貢獻,榮獲菏澤市高新技術企業獎。這一榮譽不僅是對集團技術研發能力的高度認可,也體現了其在推動區域產業升級和健康產業發展中的重要地位。
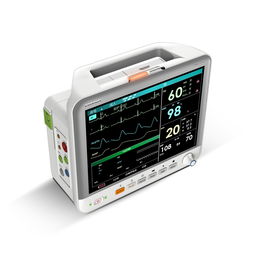
山東朱氏藥業集團作為一家專注于醫療器械研發與生產的企業,始終堅持以科技創新為核心驅動力。通過引進先進的生產設備、優化工藝流程,并與多家科研機構合作,集團在智能化醫療設備、醫用耗材等領域取得了顯著突破。其產品廣泛應用于臨床診療,有效提升了醫療服務的效率與質量,贏得了市場與用戶的一致好評。
此次獲得高新技術企業獎,標志著山東朱氏藥業集團在技術成果轉化、知識產權保護及產業化應用方面走在了行業前列。集團負責人表示,未來將繼續加大研發投入,深耕醫療器械領域,積極響應國家‘健康中國’戰略,為推動醫療科技進步和地方經濟發展貢獻更多力量。這一獎項也將激勵更多企業投身高新技術產業,共同促進菏澤市乃至山東省的創新驅動發展。
如若轉載,請注明出處:http://m.tgcolor.cn/product/39.html
更新時間:2026-04-14 09:21:00