抖音背后的數字巨人 揭秘其服務器規模與海量并發支撐之道

在數字娛樂的浪潮中,抖音以其絲滑的瀏覽體驗和幾乎無處不在的內容推送,成為了全球數億用戶日常生活的一部分。當千萬級用戶同時刷新、上傳、互動時,支撐這一切平穩運行的,是一個龐大、復雜且高度智能的技術基礎設施體系。人們不禁好奇:抖音的服務器究竟有多大?它又是如何做到同時服務如此海量用戶的?
一、 服務器規模:一個分布式的數字帝國
抖音的服務器并非集中在一個“巨型機房”里,而是一個遍布全球的分布式服務器集群網絡。其具體規模屬于商業核心機密,但我們可以通過公開數據和行業洞察窺見一斑:
- 體量估算:根據其母公司字節跳動的公開資料及行業分析,為支撐抖音(及其國際版TikTok)全球超過10億的月活躍用戶,其服務器總量很可能達到了數百萬臺的級別。這些服務器分布在全球數十個國家和地區的主要數據中心,如美國、新加坡、愛爾蘭、印度等,以實現用戶就近訪問,降低延遲。
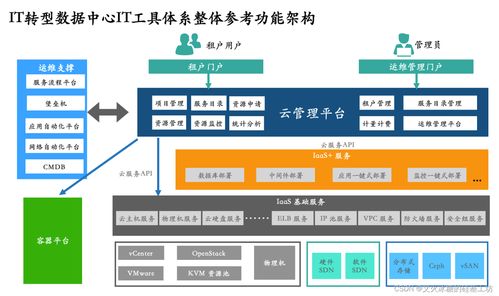
- 架構特點:采用微服務架構和混合云策略。抖音并非完全自建所有數據中心,而是結合了自建IDC(互聯網數據中心)與租用大型公有云服務(如AWS、Google Cloud等)的方式,形成混合云。這種架構極具彈性,可以根據流量峰谷(如節假日、大型活動期間)快速伸縮資源,避免資源浪費或服務崩潰。
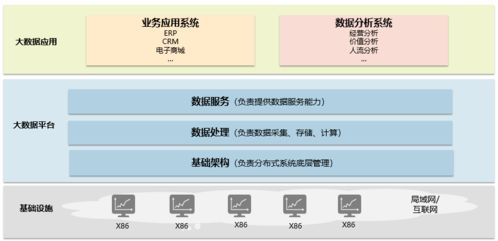
二、 核心支撐:數據處理與存儲的“三板斧”
僅僅有龐大的服務器數量還不夠,如何高效地組織、處理和存儲天量數據,才是應對高并發的關鍵。抖音主要依靠以下三大技術支柱:
1. 智能負載均衡與內容分發網絡(CDN)
這是應對高并發的第一道防線。
- 負載均衡器:像交通指揮中心,將來自用戶的海量請求智能地分發到后端不同的服務器集群,防止單臺服務器過載。
- CDN網絡:抖音在全球部署了極其龐大的CDN節點。當你刷到一個熱門視頻時,視頻文件很可能就存儲在離你物理距離最近的CDN節點上,而非遙遠的中心服務器。這實現了毫秒級的視頻加載速度,極大地緩解了中心數據中心的壓力。
2. 高效的數據處理與流計算
抖音的“推薦算法”聞名于世,其背后是實時數據處理能力的體現。
- 流式數據處理平臺:用戶每一次的點贊、評論、停留時長、轉發等行為,都會作為一條數據流實時發送到后端。抖音使用自研的(如火山引擎)或開源的流處理框架(如Apache Flink、Kafka),對這些數據進行實時分析。
- 實時推薦與計算:系統在毫秒到秒級內,根據你的實時行為更新用戶畫像,并從海量視頻庫中匹配出你可能感興趣的下一個視頻。這個過程需要驚人的計算能力,依賴于分布式的計算集群。
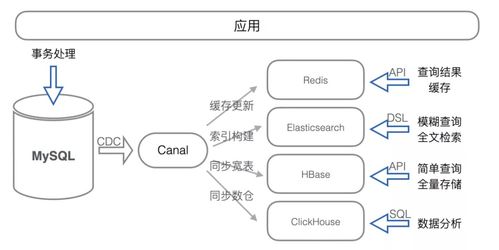
3. 分層與分片的存儲系統
面對每天數以億計的新增視頻和PB級的數據增長,存儲系統必須既龐大又敏捷。
- 分層存儲:數據根據熱度和訪問頻率被存儲在不同介質中。熱點視頻(剛發布或正流行的)存放在高速SSD存儲中,確保瞬間讀取;溫數據和冷數據(較早的視頻)則逐漸遷移到大容量、低成本的機械硬盤或歸檔存儲中,優化成本。
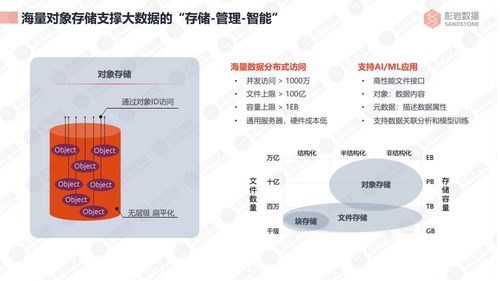
- 分布式數據庫與對象存儲:
- 用戶關系、評論、消息等結構化數據,存儲在經過深度優化的分布式數據庫(如自研或改進的MySQL集群)中,并通過分庫分表技術將數據分散到多臺服務器,提升讀寫性能。
- 視頻、圖片等非結構化海量文件,則存放在對象存儲系統中。這類系統具有近乎無限的擴展能力,是保存抖音核心資產——UGC視頻內容的“數字倉庫”。
三、 應對峰值:彈性伸縮與混沌工程
抖音的流量并非平穩,晚間高峰、熱門話題引爆、明星直播都會帶來瞬間流量洪峰。為此,抖音技術團隊還運用了更先進的手段:
- 自動化彈性伸縮:基于實時監控,系統可以自動在云平臺申請或釋放服務器資源,實現“用時擴容,閑時收縮”。
- 全鏈路壓測與混沌工程:他們會模擬“雙十一”級別的流量,對生產環境進行全鏈路壓力測試,甚至主動注入故障(如隨機關閉某臺服務器),以檢驗系統的冗余性和自愈能力,確保在真實意外發生時服務不中斷。
###
因此,抖音服務器的“大”,并不僅僅體現在物理數量上,更體現在其地理分布的廣度、架構設計的彈性、軟件系統的智能化以及運維體系的先進性上。它是一個將云計算、大數據、人工智能和網絡工程技術深度融合的超級工程。正是這個隱藏在“推薦”按鈕和滑動屏幕背后的數字巨人,支撐起了我們指尖上流暢而多彩的視聽世界。它不斷演進,以應對下一個用戶量級和更復雜交互形式的挑戰。
如若轉載,請注明出處:http://m.tgcolor.cn/product/62.html
更新時間:2026-03-13 16:09:15